In de afgelopen maanden heeft Facebook aangekondigd dat zij Graph Search, onder de naam van Unicorn, voor haar gebruikers zal introduceren. Voor deze technieken is het noodzakelijk ook een andere dan de main-stream database techniek, relational DBMS toe te passen. Deze nieuwe database techniek staat bekend onder Graph Databases en die nemen een enorme vlucht en er zijn inmiddels veel aanbieders van deze alternatieve manier om databases te bouwen. De belangrijste aanbieder is Neo4j een open-source database manager. De hype in Graph Database toepassing is naast de Facebook Search Tool vooral te vinden in online dating.
Er zijn een paar belangrijke redenen waarom Graph databases beter en sneller de informatie behoefte van gebruikers zal verbeteren en de producenten van diensten zal helpen om snel, accuraat en voor grote hoeveelheden data die informatiebehoefte zal kunnen invullen.
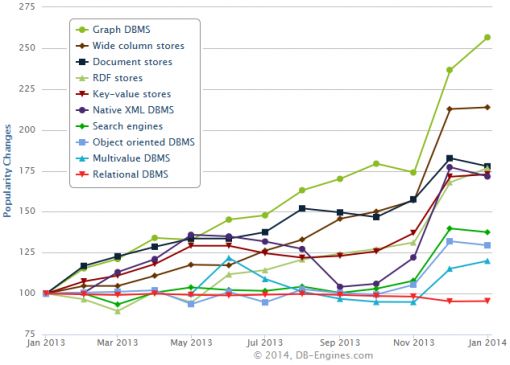
Hoewel de traditionele databases veruit in de meerderheid zijn, groeit het gebruik van Graph Databases spectaculair.
Het succes van de relationele databases komt uit het tijdperk dat computeres en de software voornamelijk gericht waren op het automatiseren van bedrijfsprocessen. Die techniek is niet goed toepasbaar op de netwerken van informatie zoals we die op het internet vinden en opbouwen. Sociale netwerken heten niet voor niets ‘netwerken.
Volgens db-engine.com groeit het aantal toepassingen van Graph databases spectaculair:
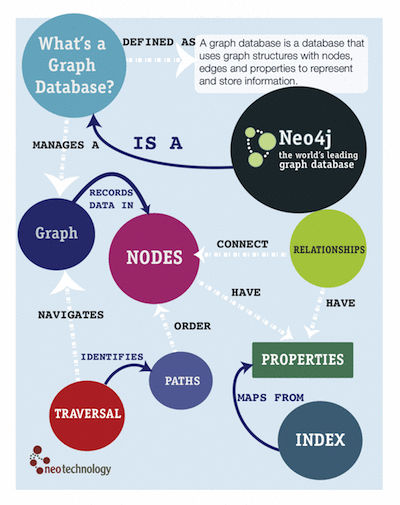
Graph Databases representeren hun data in ‘nodes’ (knooppunten) en ‘edges’ (pijlen met een richting). Die edges geven relaties tussen de nodes, die staan voor een object, begrip, handeling, item, naam(woord, status of categorie. Bijna alle informatie is op die manier te ordenen met als voordeel dat ieder object als node uniek is en daardoor een database technisch eenvoudig is te onderhouden. Alleen het aantal relaties naar andere (relevante) nodes kan per item variëren en de wolk van nodes met de omliggende gerelateerde notes verrijken feitelijk de betekenis en informatie.
Wat niet moet worden onderschat is dat met name graph databases key zijn voor het opbouwen en gebruiken van databases voor wat we zijn gaan noemen ‘big data’. Immers, iedereen die ervaring heeft met Big data problematiek, weet dat je hoofdpijn kan krijgen van het mergen van verschillende (relationele databases) met eigen specifieke definities van de inhoud van de tabellen. Converteren en ‘mengen’van relationele databases is altijd een uitdaging, en dat is toch redelijk essentieel voor het functioneren van het concept van ‘Big data’!
Graph databases kunnen daarvoor een snelle en efficiënte oplossing zijn door alle elementen uit de verschillende databases feitelijk geheel in individuele elementen op te breken en als (unieke) node in een Graph database op te nemen. De record structuur en de tabellen van de relationele database worden dan graphs van de node, en omdat je alles in de kleinst mogelijk eenheid opsplitst, kan je snel en meestal geautomatiseerd gelijke betekenissen van nodes afkomstig uit verschillend database ‘bij elkaar optellen’ en daarmee de informatie verrijken en ‘mergen’.
Deze wijze van het representeren van informatie sluit perfect aan op de manier waarop wij zelf de informatie voortdurend opslaan, herinneren, herkennen. en ordenen. Wij denken in netwerken waarbij ook hiërarchieën natuurlijk perfect als een graph kunnen representeren.
De techniek van graph databases en de soort bestanden wat je daarmee kunt opbouwen en inrichten is ook weer niet helemaal nieuw. We kennen al heel lang de netwerkdatabases of the navigational databases. Je kunt de Graph database managers beschouwen als een betere implementatie daarvan, en in principe kun je alle databases die gebouwd zijn met een netwerk model representeren in een Graph database.
Een bijzondere vorm van Graph databases zijn semantische netwerken in engere zin, die in de linguïstiek vaak ontologiëen, thesauri of taxonomieën worden genoemd. Alle indexen, woordenboeken, encyclopedieën, glosseries met onderlinge verwijzingen zijn allemaal vormen van semantische netwerken (verzameling van unieke begrippen met betekenisdragende (‘zie’, ‘zie ook’, ‘deel van’, etc) onderlinge verwijzingen) en zijn dus uitstekend en efficiënt in Graph databases te bouwen.
Algemeen wordt aangenomen is dat de volgende stap in search op het internet semantic search zal zijn en de Graph databases openen feitelijk de techniek om deze zoekmethodologie ook daadwerkelijk met succes te kunnen toepassen. Het is niet verwonderlijk dat Facebook zijn Graph Search heeft uitgevonden want speciaal in sociale netwerken is de informatie vaak relaties tussen ‘vrienden’, ‘onderwerpen’ waarover men schrijft, en verwijzingen naar informatie op het web. Dat relationele karakter van informatie is ook sterk van toepassing op partnerkeuze sites, maar de toepassing zijn zo gauw je de wereld ziet door de ogen van een netwerk, werkelijk onuitputtelijk.
Zelf heb ik in de zeventiger- en tachtiger jaren van de vorige eeuw al gewerkt met het Thesaurus Systeem van Uitgeverij Het Spectrum, die – met wat we nu Graph Databases zouden noemen – als eerste uitgever in de wereld geheel met behulp van computers en databases de Grote Spectrum Encyclopedie heeft geproduceerd en één van de grootste encyclopedische semantische netwerken (500.000 geclassificeerde termen met 1,5 miljoen onderlinge relaties) heeft gebouwd. Met deze encyclopedische graph database zijn veel database publishing (on-line) projecten gerealiseerd. Voor meer informatie over semantische netwerken zie mijn presentatie: